1. Overview
GOMAP-singularity is the containerized version of the Gene Ontology Meta Annotator for Plants (GOMAP) pipeline. GOMAP is a high-throughput pipeline to annotate GO terms to plant protein sequences. The pipeline uses three different approaches to annotate GO terms to plant protein sequences, and compile the annotations together to generate an aggregated dataset. GOMAP uses Python code to run the component tools to generate the GO annotations, and R code to clean and aggregate the GO annotations from the component tools.
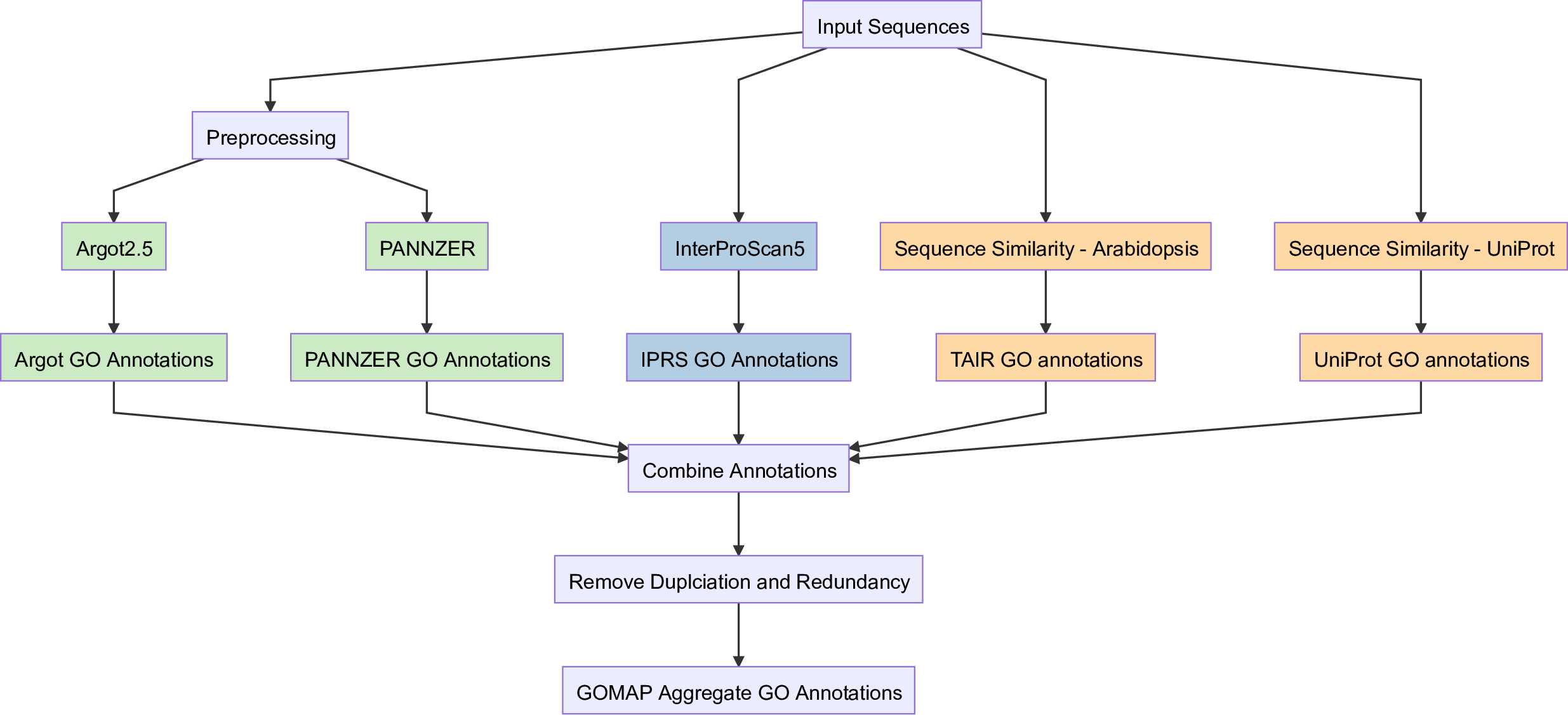
The GOMAP-singularity container is designed with two uses in mind, namely reproducability and portability. The pipeline development is still ongoing and the major bugs are fixed. We have prioritized the quality of the dataset over other features. Some anotations tools are which produce good annotations are not available in a containerized format, so the pipeline cannot be converted into a self-contained container. As new members are added to the team, and more tools are evaluated we may update the pipeline to be self-contained in future.

1.1. Methods used in GOMAP
Sequence-similarity
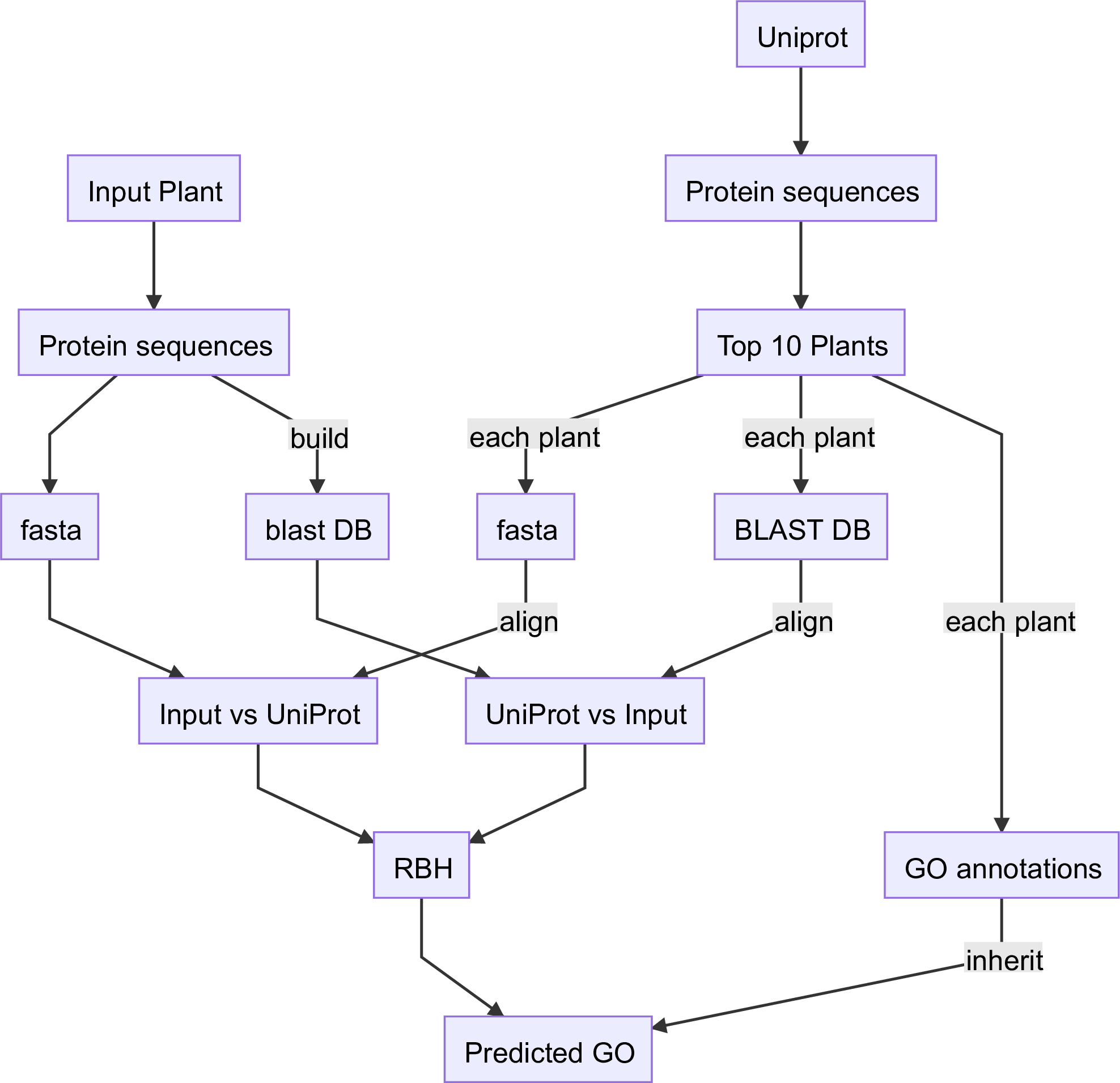
Sequence-similarity methods search for similar sequences in other species for the given input sequences, and inheric curated/reviewed GO terms from other species to maize. Two datasets are used for the sequence-similarity datasets namely Arabidopsis and UniProt .
Domain-presence
Domains-presense method searches for known protein domains and signatures in the input sequences and assign GO terms from curated domains and signatures to the input sequences
Mixed-methods
Mixed-methods or CAFA tools used in the pipeline were Argot2 and PANNZER. Both tools use information generated from sequence-similarity and domain presence to predict better Annotations from the dataset.
1.1.1. Sequence-similarity
1.1.1.1. Arabidopsis

1.1.1.2. UniProt
1.1.2. Domain-presence
Domain-presence step uses InterProScan to search for signatures present in the input sequences and annotate GO terms to protein sequences. InterProScan-5.25-64.0 was downloaded from https://github.com/ebi-pf-team/interproscan/wiki and used to annotate input sequences [5].
1.1.3. Mixed-methods
Three mix-methods have been used in GOMAP, namely Argot2.5, FANN-GO and PANNZER [6][7][8]. Argot2.5 and PANNZER require preprocessing if the input sequences before they can be used to annotate GO terms to input sequences. The overall steps for running the mixed-methods have been given in the diagram below.
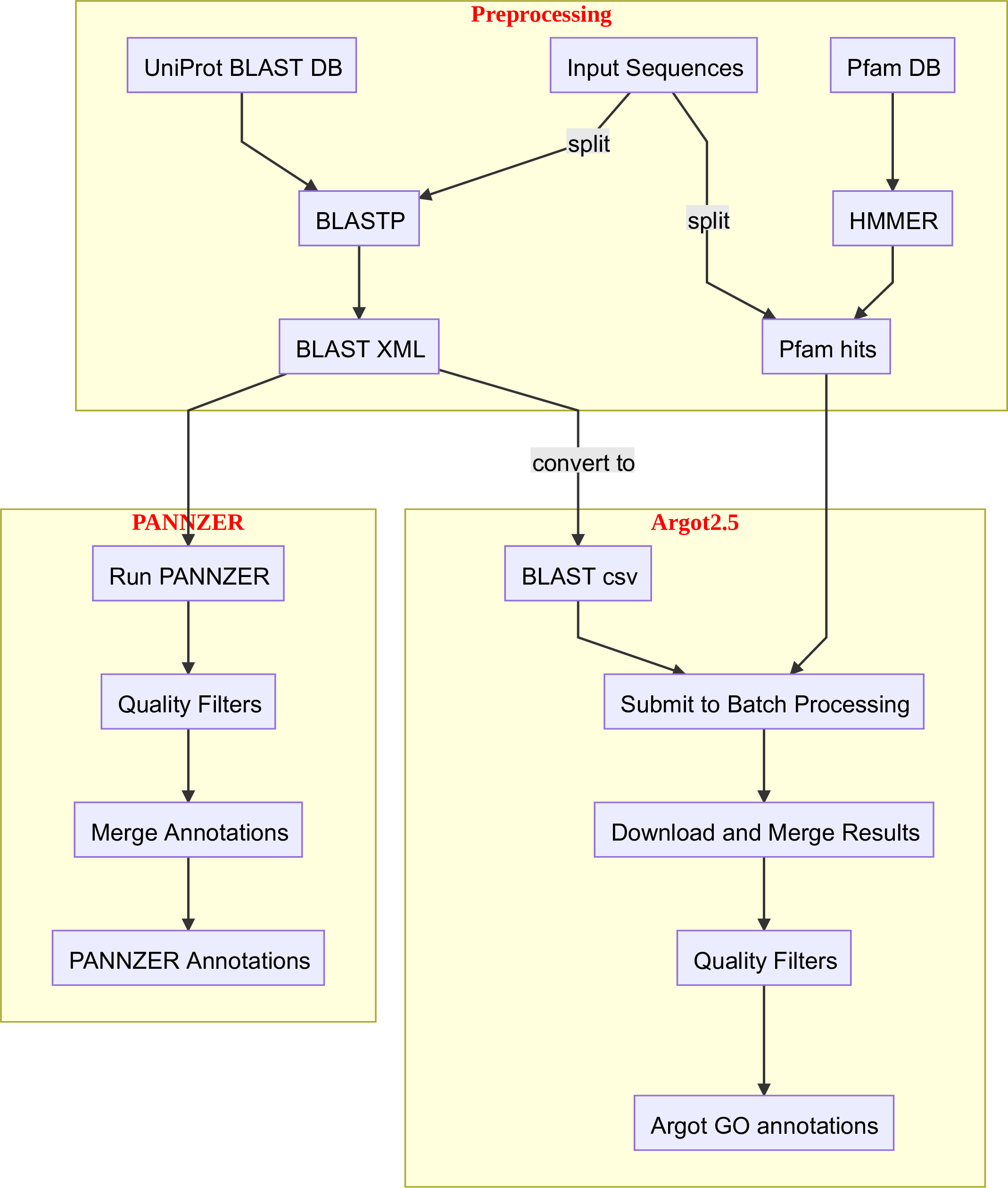
The main step common to Argot2.5 and PANNZER tools is the mixmeth-blast. This runs the BLASTP search against UniprotDB and creates the XML output for chunked input [9][2]. The XML files from the mixmeth-blast are used for annotation with PANNZER tool. The XML files are converted to CSV for Argot2.5. The Argot2.5 also requires Pfam hits for the input sequences from HMMER. These two files are submitted to Argot2.5 webserver for annotation. The annotations are retrieved after job completion emails are sent by Argot2.5.

1.2. Datasets used in GOMAP
1.2.1. Public datasets used in GOMAP
Database
Type
Format
Version
Species
Citation
TAIR
Protein Sequences
fasta
TAIR 10
Arabidopsis thaliana
TAIR
GO Annotations
gaf 2.0
TAIR 10 (20170410)
Arabidopsis thaliana
Gramene 49
Gene Annotations
gff3
5b+
Zea mays
Gramene 49
GO Annotations
gaf 2.0
5b+
Zea mays
Phytozome 11
GO Annotations
tsv
5b+
Zea mays
Uniprot
Protein sequences
fasta
20170410
All species
Uniprot
Protein sequences
fasta
20170410
All plants
Uniprot
GO Annotations
gaf 2.0
20170410
All plants
Pfam
HMMs
hmm
27.0
All species
PANTHER
HMMs
hmm
10.0
All species
1.2.2. Software tools used in GOMAP
Philippe Lamesch, Tanya Z Berardini, Donghui Li, David Swarbreck, Christopher Wilks, Rajkumar Sasidharan, Robert Muller, Kate Dreher, Debbie L Alexander, Margarita Garcia-Hernandez, Athikkattuvalasu S Karthikeyan, Cynthia H Lee, William D Nelson, Larry Ploetz, Shanker Singh, April Wensel, and Eva Huala. The arabidopsis information resource (TAIR): improved gene annotation and new tools. Nucleic Acids Res, 40(Database issue):D1202–10, jan 2012. URL: http://dx.doi.org/10.1093/nar/gkr1090 (visited on 2015-11-10), doi:10.1093/nar/gkr1090.
UniProt Consortium. UniProt: a hub for protein information. Nucleic Acids Res, 43(Database issue):D204–12, jan 2015. URL: http://dx.doi.org/10.1093/nar/gku989 (visited on 2017-02-28), doi:10.1093/nar/gku989.
Rachael P Huntley, Tony Sawford, Prudence Mutowo-Meullenet, Aleksandra Shypitsyna, Carlos Bonilla, Maria J Martin, and Claire O’Donovan. The GOA database: gene ontology annotation updates for 2015. Nucleic Acids Res, 43(Database issue):D1057–63, jan 2015. URL: http://dx.doi.org/10.1093/nar/gku1113 (visited on 2016-10-31), doi:10.1093/nar/gku1113.
David Binns, Emily Dimmer, Rachael Huntley, Daniel Barrell, Claire O’Donovan, and Rolf Apweiler. QuickGO: a web-based tool for gene ontology searching. Bioinformatics, 25(22):3045–3046, nov 2009. URL: http://dx.doi.org/10.1093/bioinformatics/btp536 (visited on 2016-10-31), doi:10.1093/bioinformatics/btp536.
Philip Jones, David Binns, Hsin-Yu Chang, Matthew Fraser, Weizhong Li, Craig McAnulla, Hamish McWilliam, John Maslen, Alex Mitchell, Gift Nuka, Sebastien Pesseat, Antony F Quinn, Amaia Sangrador-Vegas, Maxim Scheremetjew, Siew-Yit Yong, Rodrigo Lopez, and Sarah Hunter. InterProScan 5: genome-scale protein function classification. Bioinformatics, 30(9):1236–1240, may 2014. URL: http://dx.doi.org/10.1093/bioinformatics/btu031 (visited on 2015-11-10), doi:10.1093/bioinformatics/btu031.
Marco Falda, Stefano Toppo, Alessandro Pescarolo, Enrico Lavezzo, Barbara Di Camillo, Andrea Facchinetti, Elisa Cilia, Riccardo Velasco, and Paolo Fontana. Argot2: a large scale function prediction tool relying on semantic similarity of weighted gene ontology terms. BMC Bioinformatics, 13 Suppl 4:S14, mar 2012. URL: http://dx.doi.org/10.1186/1471-2105-13-S4-S14 (visited on 2016-04-29), doi:10.1186/1471-2105-13-S4-S14.
Wyatt T Clark and Predrag Radivojac. Analysis of protein function and its prediction from amino acid sequence. Proteins, 79(7):2086–2096, jul 2011. URL: http://dx.doi.org/10.1002/prot.23029 (visited on 2016-10-28), doi:10.1002/prot.23029.
Patrik Koskinen, Petri Törönen, Jussi Nokso-Koivisto, and Liisa Holm. PANNZER: high-throughput functional annotation of uncharacterized proteins in an error-prone environment. Bioinformatics, 31(10):1544–1552, may 2015. URL: http://dx.doi.org/10.1093/bioinformatics/btu851 (visited on 2016-10-28), doi:10.1093/bioinformatics/btu851.
S F Altschul, W Gish, W Miller, E W Myers, and D J Lipman. Basic local alignment search tool. J Mol Biol, 215(3):403–410, oct 1990. URL: http://dx.doi.org/10.1016/S0022-2836(05)80360-2 (visited on 2016-03-08), doi:10.1016/S0022-2836(05)80360-2.
Marcela K Tello-Ruiz, Joshua Stein, Sharon Wei, Justin Preece, Andrew Olson, Sushma Naithani, Vindhya Amarasinghe, Palitha Dharmawardhana, Yinping Jiao, Joseph Mulvaney, Sunita Kumari, Kapeel Chougule, Justin Elser, Bo Wang, James Thomason, Daniel M Bolser, Arnaud Kerhornou, Brandon Walts, Nuno A Fonseca, Laura Huerta, Maria Keays, Y Amy Tang, Helen Parkinson, Antonio Fabregat, Sheldon McKay, Joel Weiser, Peter D’Eustachio, Lincoln Stein, Robert Petryszak, Paul J Kersey, Pankaj Jaiswal, and Doreen Ware. Gramene 2016: comparative plant genomics and pathway resources. Nucleic Acids Res, 44(D1):D1133–40, jan 2016. URL: http://dx.doi.org/10.1093/nar/gkv1179 (visited on 2016-10-31), doi:10.1093/nar/gkv1179.
David M Goodstein, Shengqiang Shu, Russell Howson, Rochak Neupane, Richard D Hayes, Joni Fazo, Therese Mitros, William Dirks, Uffe Hellsten, Nicholas Putnam, and Daniel S Rokhsar. Phytozome: a comparative platform for green plant genomics. Nucleic Acids Res, 40(Database issue):D1178–86, jan 2012. URL: http://dx.doi.org/10.1093/nar/gkr944 (visited on 2017-08-24), doi:10.1093/nar/gkr944.
Robert D Finn, Alex Bateman, Jody Clements, Penelope Coggill, Ruth Y Eberhardt, Sean R Eddy, Andreas Heger, Kirstie Hetherington, Liisa Holm, Jaina Mistry, Erik L L Sonnhammer, John Tate, and Marco Punta. Pfam: the protein families database. Nucleic Acids Res, 42(Database issue):D222–30, jan 2014. URL: http://dx.doi.org/10.1093/nar/gkt1223 (visited on 2015-11-10), doi:10.1093/nar/gkt1223.
Huaiyu Mi, Xiaosong Huang, Anushya Muruganujan, Haiming Tang, Caitlin Mills, Diane Kang, and Paul D Thomas. PANTHER version 11: expanded annotation data from gene ontology and reactome pathways, and data analysis tool enhancements. Nucleic Acids Res, 45(D1):D183–D189, jan 2017. URL: http://dx.doi.org/10.1093/nar/gkw1138 (visited on 2019-01-30), doi:10.1093/nar/gkw1138.
Robert D Finn, Jody Clements, and Sean R Eddy. HMMER web server: interactive sequence similarity searching. Nucleic Acids Res, 39(Web Server issue):W29–37, jul 2011. URL: http://dx.doi.org/10.1093/nar/gkr367 (visited on 2015-11-10), doi:10.1093/nar/gkr367.
Michael Defoin-Platel, Matthew M Hindle, Artem Lysenko, Stephen J Powers, Dimah Z Habash, Christopher J Rawlings, and Mansoor Saqi. AIGO: towards a unified framework for the analysis and the inter-comparison of GO functional annotations. BMC Bioinformatics, 12:431, nov 2011. URL: http://dx.doi.org/10.1186/1471-2105-12-431 (visited on 2016-05-10), doi:10.1186/1471-2105-12-431.